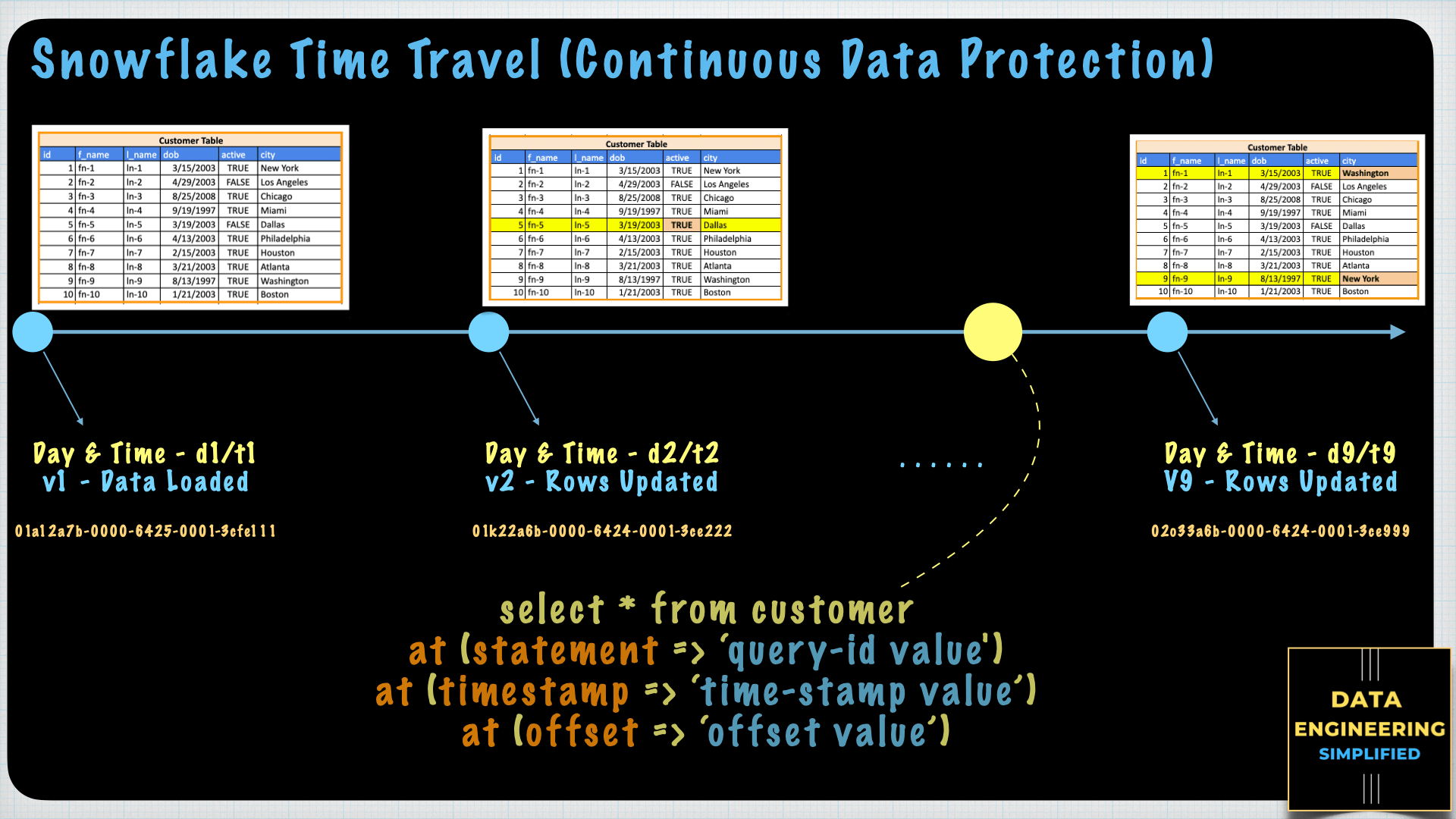
Introduction Data pipelines automate many of the manual steps involved in transforming and optimizing continuous data loads. Frequently, the “raw” data is first loaded temporarily into a staging table (stage...
scala spark spark-three datasource-v2-spark-three Spark 3.0 is a major release of Apache Spark framework. It’s been in preview from last December and going to have a stable release very soon....
Continous Data Loading is trickier thing in snowflake and how to load it wihout any external stage is evey trickier. This blog will focus how to load data using a...
Snowflake Container Hierarchy concept is very important and not understood by many developer. This blog focuses with table creation, be it standard or external or transient or temporary. It also...