Introduction
Data pipelines automate many of the manual steps involved in transforming and optimizing continuous data loads. Frequently, the “raw” data is first loaded temporarily into a staging table (stage layer) used for interim storage and then transformed using a series of SQL statements before it is inserted into the destination reporting/consumption tables.
Snowflake provides the following features to enable continuous data pipelines:
- Continuous data loading -
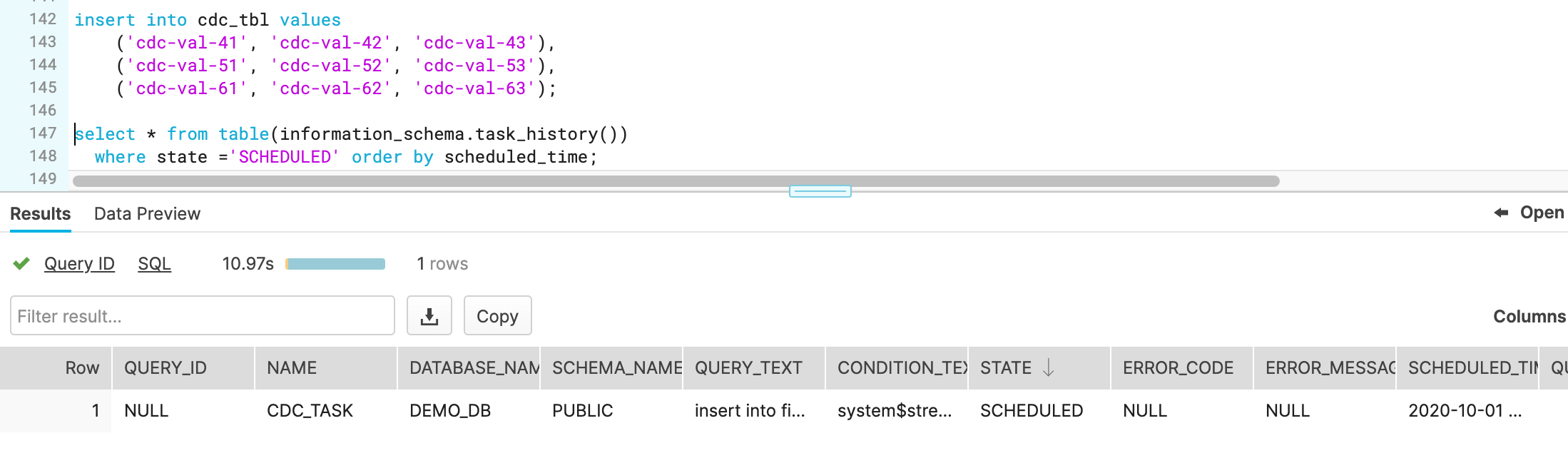
Options for continuous data loading include the following: - Snowpipe - Snowpipe continuously loads micro-batches of data from an external stage location
Snowflake Connector for Kafka - The Kafka connector continuously loads records from one or more Apache Kafka topics into an internal (Snowflake) stage and then into a staging table using SnowpipeThird-party data integration tools- Change data tracking - A stream object records the delta of change data capture (CDC) information for a table (such as a staging table), including inserts and other data manipulation language (DML) changes.
- Recurring tasks - A task object defines a recurring schedule for executing a SQL statement, including statements that call stored procedures.
In this jump start, we will focus only on stream & task and not focus on SnowPipe
Dataflow : SnowPipe->Stream->Task
The following diagram illustrates a common continuous data pipeline flow using Snowflake functionality:
Snowpipe continuously loads micro-batches of data from an external stage location (S3 or AzureBlob)- One or more table streams capture change data and make it available to query.
- One or more tasks execute SQL statements (which could call stored procedures) to transform the change data and move the optimized data sets into destination tables for analysis.
In this jump start, we will focus only on stream & task and not focus on SnowPipe
Stream & Task Jump Start Example Code
1
2
3
4
5
-- setup the context
use role sysadmin;
use database demo_db;
use schema public;
use warehouse compute_wh;
Create a table and create stream on it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
--create a raw table whiere change data capture will be triggered
create or replace table cdc_tbl (
cdc_col_1 varchar ,
cdc_col_2 varchar ,
cdc_col_3 varchar
);
--insert & select and see the data (we are loading 1st time)
insert into cdc_tbl values
('onetime-val-11', 'onetime-val-12', 'onetime-val-13'),
('onetime-val-21', 'onetime-val-22', 'onetime-val-23'),
('onetime-val-31', 'onetime-val-32', 'onetime-val-33');
select * from cdc_tbl;
--the final table where post cdc, data will
create or replace table final_tbl (
final_col_1 varchar ,
final_col_2 varchar ,
final_col_3 varchar
);
-- 1st time data load from cdc_table to final table, we can assume history load or onetime load
insert into final_tbl select * from cdc_tbl;
select * from final_tbl;
Define the stream on the top of cdc_table
1
2
3
create or replace stream
cdc_stream on table cdc_tbl
append_only=true;
Lets load these new CDC data to final table
1
2
3
4
5
6
7
create or replace task cdc_task
warehouse = compute_wh
schedule = '5 minute'
when
system$stream_has_data('cdc_stream')
as
insert into final_tbl select * from cdc_stream;
Now stream and task are created, we need to activate the task to start consuming it
1
2
use role accountadmin;
alter task cdc_task resume;
Now load the cdc data in cdc_table, and these data set will appear stream data set
1
2
3
4
insert into cdc_tbl values (
'cdc-val-41', 'cdc-val-42', 'cdc-val-43'),
('cdc-val-51', 'cdc-val-52', 'cdc-val-53'),
('cdc-val-61', 'cdc-val-62', 'cdc-val-63');
Now check if stream is running in every 10min
1
2
3
4
5
6
-- how to see how it works
select * from table(information_schema.task_history())
order by scheduled_time;
-- you can see only the schedule items
select * from table(information_schema.task_history())
where state ='SCHEDULED' order by scheduled_time;